В конце 1970-х и начале 1980-х годов британскими учеными Стивеном Робертсоном и Карен Спар Джоунс был разработан алгоритм bm25, который представляет собой вероятностно-поисковой механизм. Он используется для ранжирования документов по их релевантности к поисковому запросу. Суть работы алгоритма bm25 заключается в том, что каждый документ анализируется, а затем значения применяются в специальной формуле, которая учитывает их отношение к другим документам в коллекции. На основании этого расчета выдается конечная оценка, которая влияет на позицию документа в поисковой выдаче. В целом, алгоритм bm25 является важным инструментом для оптимизации ранжирования результатов поиска.
ИНТЕРЕСНО. Функцию bm25 также часто называют «Okapi bm25», в честь поисковой системы, разработанной в Лондонском городском университете в 1980-х и 1990-х годах. Эта система, названная в честь африканского животного окапи, использовала алгоритм bm25 для ранжирования результатов поиска.
Как ведется расчет алгорима ранжирования
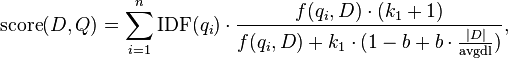
Расчет оценки релевантности документа D к запросу Q с использованием алгоритма bm25 включает несколько ключевых параметров.
- f(qi,D) представляет собой частоту слова qi в документе D. ∣D∣ — длина документа, которая рассчитывается как количество слов в нем.
- avgdl представляет среднюю длину документа в коллекции.
- k1 и b — это свободные коэффициенты, которые часто выбираются как k1=2.0 и b=0.75.
- IDF(qi) представляет собой обратную документную частоту слова qi. В классическом варианте bm25 формула для IDF(qi) определяется как:
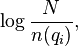
где N — общее количество документов в коллекции, а n(qi) — количество документов, содержащих qi.
Однако существуют различные адаптированные формулы для IDF(qi), одна из которых выглядит следующим образом:
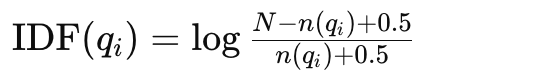
Эти параметры используются в формуле bm25 для расчета оценки релевантности документа к запросу.
Недостаток формулы IDF bm25
В формуле IDF bm25 существует недостаток: для слов, встречающихся более чем в половине документов коллекции, значение IDF может стать отрицательным. Это может привести к неожиданным результатам, когда вторичный документ без данного слова оценивается выше, чем первичный документ с этим словом. Такой эффект может быть нежелательным при расчете релевантности документов.
Для устранения этого недостатка могут использоваться различные корректировки формулы IDF:
- Игнорирование высокочастотных слов: можно проигнорировать все высокочастотные слова в тексте, например, занесением их в стоп-лист.
- Установление нижней границы ( varepsilon ) для IDF: если значение IDF становится меньше определенного порога ( varepsilon ), оно принимается равным ( varepsilon ).
- Использование другой формулы IDF: можно применить альтернативную формулу IDF, которая не допускает отрицательных значений.
Эти коррекции позволяют избежать нежелательных эффектов при расчете релевантности с помощью алгоритма bm25.
BM25°F
BM25°F представляет собой модификацию алгоритма bm25, где документ рассматривается как составной элемент, состоящий из нескольких блоков, таких как ссылочный текст, заголовки (например, h1-h3), и основной текст. Каждый из этих блоков имеет свою длину, которая независимо нормализуется, то есть приводится к некоторой стандартизированной форме.
Важным аспектом BM25°F является то, что каждому участку документа назначается своя степень значимости в итоговой функции ранжирования. Например, заголовки могут считаться более важными, чем обычный текст, а ссылочный текст может иметь свои уникальные веса. Это позволяет более гибко учитывать структуру документа и уровень важности каждого его компонента при определении его релевантности к поисковому запросу.
Таким образом, BM25°F расширяет возможности алгоритма bm25, позволяя более точно учитывать различные части документа при ранжировании результатов поиска.
Что в итоге?
Алгоритмы поисковых систем, включая их методы ранжирования, являются стратегическими ресурсами, и многие детали этих алгоритмов остаются коммерческой тайной. Это обусловлено не только желанием защитить интеллектуальную собственность, но и поддержанием эффективности и качества поисковых результатов.
Раскрытие всех деталей алгоритмов ранжирования может стать предметом злоупотреблений, таких как попытки манипулировать поисковыми результатами в своих интересах, что может негативно повлиять на пользовательский опыт и доверие к поисковой системе.
Однако, даже не зная всех деталей алгоритмов, SEO-оптимизаторы могут использовать различные методы и стратегии для улучшения видимости в поисковых результатах, включая адаптацию контента, улучшение пользовательского опыта на сайте, и использование надежных техник ссылочного профиля.
В конечном итоге, основная цель поисковых систем — предоставить пользователям наиболее релевантные и полезные результаты по их запросам, и в этом контексте, сохранение тайны некоторых аспектов алгоритмов становится важным элементом поддержания этой цели.